
Provided by: po4a_0.52-1_all 
名前
po4a - ドキュメントやその他の素材の翻訳フレームワーク
概要
po4a (PO for anything) プロジェクトは、gettext ツールが想定していないドキュメントのような
領域で翻訳をしやすくすること (またより興味深いのは、翻訳文の保守がしやすくなること) を目標
にしています。
目次
このドキュメントは以下のような構成となっています:
1 なぜ po4a を使うべきなのでしょうか? 何の役に立つのですか?
この導入の章では、プロジェクトの動機とその哲学について説明します。翻訳を行うに当たって
po4a を評価中であるなら、まずこの章を読んでください。
2 po4a の使い方は?
この章は、処理全体を理解していただけるようにユーザの質問に答える形のリファレンスマニュ
アルの一種です。po4a をどのように使用するかを紹介し、特定のツールのドキュメントへの導
入として役立ちます。
新規翻訳を始めるには?
翻訳をドキュメントファイルに適用するには?
po4a 翻訳を更新するには?
既存の訳を po4a にコンバートするには?
翻訳におまけのテキスト (翻訳者名など) を追加するには?
一度のプログラム実行でこのすべてを行うには?
po4a をカスタマイズするには?
3 どのように動作しますか?
この章では、保守改良を自信を持って助けていただけるよう po4a 内部の概要を説明します。ま
た、なぜ思ったように動作しないか、どのように問題を解決すればいいかを理解する助けになる
かもしれません。
4 FAQ
本章ではよく訊かれる質問を分類します。実際、以下のような形でほとんどの質問を定型化でき
ました。「なぜああではなく、このような設計をしたのですか?」 po4a がドキュメントを翻訳
する正しい方法ではないと感じたら、この節を読むようにするべきです。あなたの疑問への答え
にならないなら、<po4a-devel@lists.alioth.debian.org> メーリングリストで私たちにお問い
合わせください。私たちはフィードバックが大好きです。
5 モジュール固有の記述
この章では、翻訳者とオリジナルの作者の視点で、それぞれのモジュールの仕様を示していま
す。翻訳生活をより楽にするために、このモジュールで翻訳する際に遭遇する文法や、オリジナ
ルのドキュメントが従わなければならないルールについて学ぶには、これをお読みください。
この節は実際には本ドキュメント本来の部分ではなく、各モジュールのドキュメントにありま
す。これにより、ドキュメントとコードを共に保守し、確実に情報が最新となるのを助けます。
なぜ po4a を使うべきなのでしょうか? 何の役に立つのですか?
誰でもソフトウェアやそのソースコードにアクセスできるようにするオープンソースの考え方が私は
好きです。しかしフランス人であり、ソフトウェアのオープン度がライセンスのみでないことをよく
意識しています。翻訳されていないフリーソフトウェアは、非英語圏の人々には役に立たないので
す。ですから本当に誰でも利用できるように、まだ作業を行っています。
オープンソース活動家のこの状況の認知度は、最近劇的に向上しました。翻訳者として最初の戦いに
勝利し、翻訳の重要性を周知できました。しかし残念ながら、これはまだ簡単な部類でした。今度
は、すべてを翻訳するよう作業しなければなりません。
実際には、オープンソースソフトウェア自身は、すばらしい gettext ツール群のおかげでかなりき
ちんと翻訳の恩恵にあずかっています。これはプログラムから翻訳する文字列を抽出し、翻訳者に決
まった形で提供し、実行時には、作業の成果である翻訳済みのメッセージをユーザに表示できます。
しかし、ドキュメントに関しては状況が大きく異なります。あまりにも頻繁に、翻訳されたドキュメ
ントが十分見えるようになっていない (プログラムの一部として配布されない)、一部しか訳されて
いない、更新されていないといったことが起きています。最後の状況はあり得る中で最悪なもので
す。古い翻訳がもはや使われなくなった古い動作を説明しているため、まったく翻訳されていない状
況よりもひどい結果になります。
解決すべき問題
ドキュメントの翻訳は、本来そんなに難しくありません。テキストはプログラムのメッセージよりも
ずっと長く、訳了するのに時間がかかりますが、技術スキルが本当に必要というわけではないので
す。難しい部分は成果物を保守しようとしたときに現れます。変更箇所や更新すべき箇所を探し出す
のは非常に難しく、誤りやすく、苦痛をともなう作業です。世の中にこんなにも時代遅れなドキュメ
ントが存在しているのは、これが原因だと考えています。
po4a の回答
そこで、po4a の核心は、ドキュメントの翻訳を保守できるようにすることです。そのアイデア
は、この新しい分野に gettext の方法論を再利用することです。gettext のように、翻訳者に一様
なフォーマットで提示するために、テキストはそのオリジナルの場所から抽出されます。オリジナル
の新しいリリースが出てきた時に、古典的な gettext ツールは翻訳者が翻訳を更新するのを手助け
します。しかし、古典的な gettext モデルとは異なり、翻訳はオリジナルドキュメントの構造に再
度注入され、翻訳は英語バージョンと同じように処理や配布をすることができます。
このおかげで、ドキュメントのどこが変更され、修正する必要があるかを見つけるのが、非常に簡単
になりました。ほかの長所としては、オリジナルドキュメントの構造が根本的に再編成されて、章が
移動、結合、分割されたとしても、ほとんどすべての作業をツールが行うということもあります。翻
訳用にドキュメント構造からテキストを抽出することで複雑なテキストフォーマットに触らずに済
み、ドキュメントを壊してしまう可能性を (完全になくすというわけには行きませんが) 低くできま
す。
このアプローチの利点と欠点のより詳しい一覧は、このドキュメントの後ろの FAQ を参照してくだ
さい。
サポートするフォーマット
現在、このアプローチで実装に成功しているのは、以下のテキスト整形フォーマットです:
man
たくさんのプログラムで使われている、古き良きマニュアルページのフォーマットです。このフォー
マットはいくらか難しく、初心者には本当に易しくないので po4a のサポートは非常に歓迎されてい
ます。Locale::Po4a::Man(3pm) モジュールは、BSD man ページ (Linux でも本当に一般的) で使用
されている mdoc フォーマットもサポートしています。
pod
Perl のオンラインドキュメントフォーマットです。言語や拡張機能自体が、既存の Perl スクリプ
トと同じように記述されています。同じファイルに組み込んで、実際のコードのそばにドキュメント
を記述し保守しやすくしています。プログラマーの生活は楽になりますが、残念ながら翻訳者の生活
は楽にはなりません。
sgml
最近はいくらか XML に取って代わられましたが、このフォーマットは数画面以上の長いドキュメン
トでまだかなり頻繁に使用されます。これで完全な本を作ることができます。あまりにもドキュメン
トが長いため、翻訳を更新するのはまさしく悪夢といえます。また、オリジナルドキュメントを更新
すると、インデントが再構成されるため、diff もあまり役に立ちません。幸い、po4a はこの処理で
も助けになります。
現在、DebianDoc と DocBook DTD のみサポートしていますが、新しくサポートするものを追加する
のは、本当に簡単です。また、コマンドラインに必要な情報を与え、コードを変更せずに未知の
SGML DTD を po4a で使用することもできます。詳細は Locale::Po4a::Sgml(3pm) を参照してくださ
い。
TeX / LaTeX
LaTeX フォーマットはフリーソフトウェア界や出版界で使われている有名なフォーマットで
す。Locale::Po4a::LaTeX(3pm) モジュールは Python のドキュメントや書籍、各種発表でテストさ
れています。
texinfo
GNU のドキュメントはすべてこのフォーマットで書かれています (公式 GNU プロジェクトになる必
要条件の一つです)。po4a のLocale::Po4a::Texinfo(3pm) サポートは始まったばかりです。バグ報
告や機能のリクエストをお願いします。
xml
XML フォーマットは多くのドキュメントフォーマットの基礎になっています。
現在、po4a では DocBook の DTD をサポートしています。詳細は、Locale::Po4a::Docbook(3pm) を
参照してください。
その他
Po4a can also handle some more rare or specialized formats, such as the documentation of
compilation options for the 2.4+ Linux kernels or the diagrams produced by the dia tool.
Adding a new one is often very easy and the main task is to come up with a parser of your
target format. See Locale::Po4a::TransTractor(3pm) for more information about this.
サポート外のフォーマット
残念ながら、po4a はいくつかのドキュメントフォーマットのサポートを欠いています。
ドキュメントだけではなく、po4a でサポートしたいほかのフォーマットがたくさんあります。まさ
しく私たちは、古典的な gettext ツールが残した「市場の穴」を埋めるのを目標としています。そ
こには、パッケージの説明 (deb や rpm) や、パッケージのインストールスクリプトの質問、パッ
ケージの changelog、ゲームのシナリオや wine リソースファイルといったプログラムが使用するす
べての特殊ファイルが含まれます。
po4a の使い方は?
この章は、処理全体を理解していただけるようにユーザの質問に答える形のリファレンスマニュアル
の一種です。po4a をどのように使用するかを紹介し、特定のツールのドキュメントへの導入として
役立ちます。
概要図
以下の図は po4a を用いたドキュメント翻訳過程の概要です。複雑になってしまいましたが、おじけ
づかないでください。処理の 全体 を表そうとして、このようになってしまいました。いったんプロ
ジェクトを po4a に変換すると図の右の部分のみが関係します。
Note that master.doc is taken as an example for the documentation to be translated and
translation.doc is the corresponding translated text. The suffix could be .pod, .xml, or
.sgml depending on its format. Each part of the picture will be detailed in the next
sections.
master.doc
|
V
+<-----<----+<-----<-----<--------+------->-------->-------+
: | | :
{translation} | { update of master.doc } :
: | | :
XX.doc | V V
(optional) | master.doc ->-------->------>+
: | (new) |
V V | |
[po4a-gettextize] doc.XX.po -->+ | |
| (old) | | |
| ^ V V |
| | [po4a-updatepo] |
V | | V
translation.pot ^ V |
| | doc.XX.po |
| | (fuzzy) |
{ translation } | | |
| ^ V V
| | {manual editing} |
| | | |
V | V V
doc.XX.po --->---->+<---<-- doc.XX.po addendum master.doc
(initial) (up-to-date) (optional) (up-to-date)
: | | |
: V | |
+----->----->----->------> + | |
| | |
V V V
+------>-----+------<------+
|
V
[po4a-translate]
|
V
XX.doc
(up-to-date)
左側で、po4a を使用していない翻訳のこのシステムへの変換を表します。右側の先頭でオリジナル
の作者の行動 (ドキュメントの更新) を描いています。右側の中盤で po4a が自動で行う動作を描い
ています。新しい要素を抽出し、既存の翻訳と比較しています。変更のなかった部分には以前の翻訳
を使います。一部変更がある部分には、以前の翻訳を使いますが、翻訳を更新する必要があるという
マークが付きます。図の下部は、整形済みドキュメントがどのように組み立てられるかを示していま
す。
実際には、翻訳者として唯一手で操作しなければならないのは {手動編集} と印が付いている部分で
す。あぁ申し訳ありません。po4a は翻訳の助けにはなりますが、翻訳をしてくれるわけではありま
せん……
新規翻訳を始めるには?
この節では、po4a で新しく翻訳を始めるのに必要な手順を説明します。既存プロジェクトをこのシ
ステムに変換する方法は、関連する節で詳しく取り扱います。
po4a を用いて新しく翻訳を始めるには、以下の手順を行う必要があります:
- オリジナルの <master.doc> ドキュメントから、翻訳するテキストを新しい翻訳テンプレート
<translation.pot> ファイル (gettext フォーマット) に抽出します。これには po4a-gettextize
プログラムを以下のように使います:
$ po4a-gettextize -f <format> -m <master.doc> -p <translation.pot>
<format> は、当然 master.doc ドキュメントで使用されるフォーマットです。予想されたよう
に、出力は translation.pot になります。既存のオプションの詳細は po4a-gettextize(1) を参
照してください。
- Actually translate what should be translated. For that, you have to rename the POT file
for example to doc.XX.po (where XX is the ISO 639-1 code of the language you are
translating to, e.g. fr for French), and edit the resulting file. It is often a good
idea to not name the file XX.po to avoid confusion with the translation of the program
messages, but this your call. Don't forget to update the PO file headers, they are
important.
実際の翻訳には、Emacs や Vi の PO mode、Lokalize (KDE ベース)、Gtranslator (GNOME ベー
ス)、その他 (例えば Virtaal) より、あなたが作業しやすいものを使うことができます。
翻訳作業について詳しく学びたい場合は、間違いなく gettext-doc パッケージにある gettext の
ドキュメントを参照する必要があります。
翻訳をドキュメントファイルに適用するには?
翻訳を完了したら、翻訳されたドキュメントを取得し、オリジナルのものと一緒にユーザに提供した
いと思います。そのために、以下のように po4a-translate(1) プログラムを使用してください (XX
の箇所は言語コードです):
$ po4a-translate -f <format> -m <master.doc> -p <doc.XX.po> -l <XX.doc>
As before, <format> is the format used in the master.doc document. But this time, the PO
file provided with the -p flag is part of the input. This is your translation. The output
goes into XX.doc.
詳細は po4a-translate(1) を参照してください。
po4a 翻訳を更新するには?
オリジナルの master.doc ファイルが変更された時に翻訳を更新するには、po4a-updatepo(1) を以
下のように使用します:
$ po4a-updatepo -f <format> -m <new_master.doc> -p <old_doc.XX.po>
(詳細は po4a-updatepo(1) を参照してください)
当然のことながら、この操作でドキュメントの新しい段落が魔法のように PO ファイルで翻訳されて
いるということはありません。PO ファイルを手で更新する必要があります。さらに、少し変更され
た段落のために翻訳を手直しする必要があります。変更された段落を見逃さないように、処理中に
"fuzzy" マーカが付けられるので、po4a-translate でその翻訳を処理する前に、のマーカを消さな
ければなりません。最初の翻訳と同様に、作業しやすい PO エディタを使うのがベストです。
未訳部や fuzzy な部分を取り除いて PO ファイルを再度最新にしたら、前節で説明したように翻訳
済みドキュメントファイルを生成できます。
既存の訳を po4a にコンバートするには?
オリジナルの master.doc ドキュメントが大きく再編成されるまでは、手で翻訳するのに不満はな
かったでしょう。diff のようなツールがうまくいかなくなったから po4a に乗り換えようとしてい
るのだと思います。もちろん、この処理で既存の翻訳を失いたくはありません。ご心配なく。この場
合も po4a では扱えます。これを gettext 化と呼びます。
ここで重要なのは、翻訳とオリジナルが同一の構造になっていることで、ツールがそれぞれの内容を
対応付けられることです。
あなたがツイていれば (つまり両方のドキュメントの構造が完全に一致するとか)、シームレスに一
瞬で完了します。そうでなければ、この手順になぜこんなひどい名前が付いているのか理解するで
しょう。とはいえこんなひどい作業でも準備しておくに越したことはありません。いずれにし
ろ、po4a で後々楽になるために支払う価値があると思ってください。ありがたいことに一回だけや
ればいいのです。
I cannot emphasize this too much. In order to ease the process, it is thus important that
you find the exact version which were used to do the translation. The best situation is
when you noted down the VCS revision used for the translation and you didn't modify it in
the translation process, so that you can use it.
更新されたオリジナルテキストを古い翻訳と一緒に使用するのはうまくいきません。そういったこと
もできますが、本当に大変で、できれば避けた方がいいでしょう。事実上、もう一度オリジナルテキ
ストを見つけられないなら、一番いいのはあなたのために gettext 化してくれる人を見つけること
でしょう。(あ、いや、私じゃないですよ ;)
おそらくドラマチックすぎるでしょうが、何か問題があるとしても、すべてをもう一度翻訳し直すよ
りは速いと思います。既存の Perl ドキュメントフランス語訳を gettext 化するのに、問題も あり
ました が 1 日でできました。これは 2MB のテキストで、新規に翻訳するには数ヶ月を要したで
しょう。
ではまず、手順の基本を説明します。それから何か問題があれば戻ってきてヒントを示したいと思い
ます。理解しやすいように、もう一度上記の例を使用しましょう。
翻訳した XX.doc に対応する古い master.doc を用意できたら、translation.pot ファイルを手で訳
さなくても PO ファイル doc.XX.po を直接 gettext 化できます:
$ po4a-gettextize -f <format> -m <old_master.doc> -l <XX.doc> -p <doc.XX.po>
ツイているならこれで完了です。古い翻訳を po4a に変換し、すぐに更新タスクを行えます。数節前
に説明した、最新のオリジナルドキュメントと PO ファイルの同期を取る手順に従い、翻訳を更新し
てください。
うまくいっているように見えても、この処理に誤りの入り込む余地があることに注意してくださ
い。ポイントは、po4a がオリジナルと翻訳が一致しているかどうかを理解できないということで
す。この処理の結果、すべての文字列に "fuzzy" マークが付いてしまうのはこういうわけで
す。マーカを削除する前に、注意してチェックする必要があります。
しばしば、ドキュメント構造が完全には一致せず、po4a-gettextize が正常に機能しません。この時
点で、ゲームはその腐った構造をすりあわせていく作業がすべてになります。
後にある gettext 化: どのように動作しますか? 節を読むと参考になると思います。内部処理を理
解することは、この作業の助けになります。po4a-gettextize の利点は、何か問題が発生すると、詳
しく教えてくれることです。まず、ドキュメントに構造上の食い違いがある場合、その箇所を指摘し
ます。これで一致しない文字列や、テキスト中の箇所、それらの型が分かります。さらに、そこまで
で生成した PO ファイルは gettextization.failed.po に書き出してあります。
- 翻訳者名や、翻訳に貢献した人々への謝辞といった、翻訳で追加した箇所を取り除いてくださ
い。次節で説明する追加内容に後で改めて追加できます。
- 遠慮なくオリジナルと翻訳の両方を編集してください。最も重要なのは PO ファイルを手に入れ
ることです。更新は後でできます。どちらも可能であれば、gettext 化の完了後に楽になるよ
う、前述のように翻訳側を編集するとよいでしょう。
- 必要に応じて、一部が翻訳されない問題が起きたら、そのオリジナルの一部を消してくださ
い。後で PO をドキュメントと同期すると、それらが復活するでしょう。
- 構造を少しだけ変えた (二つの段落をまとめたとか、一つの段落を分けたとか) のなら、その変
更を元に戻してください。オリジナルに問題があるなら、オリジナルの作者に連絡するべきで
しょう。あなたの翻訳の中だけを修正することは、コミュニティの一部だけのための修正で
す。さらにいえば、po4a を使用する限り不可能です ;)
- 時には、段落の内容は一致するけれども、型があわない場合があります。その修正法はフォー
マットに依存します。POD や man では、片方の行は空白で始まっているのに、もう片方はそう
ではない、ということが実際にあります。こういったフォーマットでは、そのような段落は改行
できず、別の型となります。そのようなときは空白を削除してください。おそらくタグ名のタイ
プミスでしょう。
同様に、POD では、分割行に空白が入っていたり、=item 行と item の内容の間に空行がない場
合、二つの段落を一つにまとめてしまいます。
- 時々、ファイル間で同期が取れておらず、翻訳が間違った段落に割り当てられることがありま
す。これはファイルに以前から問題があったことを示しています。gettextization.failed.po
をチェックして、同期が取れない箇所を探し、修正してください。
- 時々、po4a がオリジナルや翻訳のテキスト部分を、食べてしまったと強く思うかもしれませ
ん。gettextization.failed.po に緩く一致した箇所が、どちらも記録されます。その後、前後
の正しいものと一致するかを試して gettext 化は失敗し、正しいものが見えなくなります。初
めて私の身に起きたとき私がしたように、po4a を盛大に罵ってください。
この不幸な状況は、同じ段落がドキュメント中で繰り返されているときに起こります。この場
合、PO ファイルに新しいエントリは追加されませんが、既存のエントリに参照が追加されま
す。
So, when the same paragraph appears twice in the original but both are not translated
in the exact same way each time, you will get the feeling that a paragraph of the
original disappeared. Just kill the new translation. If you prefer to kill the first
translation instead when the second one was actually better, replace the first one
with the second.
反対に、二つの似て非なる段落が全く同じように翻訳されていると、翻訳した段落が消えてし
まったように感じることでしょう。その場合は、無駄な文字列をオリジナルの段落に追加すると
解決します ("I'm different" など)。これは同期の際に消えますが、気にしないでくださ
い。追加したテキストが十分短ければ、gettext はその翻訳と既存のテキストをマッチしま
す。(fuzzy にしますが、gettext 化した後は、すべての文字列が fuzzy になるので気にするこ
とはありません)
うまくいけば、以上の小技は gettext 化作業を助け、貴重な PO ファイルが得られるでしょ
う。ファイルの同期や、翻訳を始める準備ができています。大きなテキストの場合、最初の同期に時
間がかかる場合があることに注意してください。
例えば、初めてフランス語版 Perl ドキュメント (5.5 MB の PO ファイル) に po4a-updatepo を実
行したとき、1GHz G5 コンピュータでまるまる 2 日かかりました。ええ、48 時間です。しかしその
後は、私の古いノートパソコンで十数秒しかかかりません。これは初回の実行で、PO ファイルのほ
とんどの msgid が POT ファイルのものと一致しなかったからです。このため gettext は、もっと
も近いものを探すのに、実行コストの高い文字列近接アルゴリズムを使わなくてはなりません。
翻訳におまけのテキスト (翻訳者名など) を追加するには?
gettext アプローチのため、po4a でのテキストの追加は単にオリジナルのものにそって新しいファ
イルを編集するよりも難しくなっています。しかし、いわゆる 追加内容 のおかげで追加できます。
追加内容を、処理後のローカライズしたドキュメントに適用するパッチの類として見なすとわかりや
すいでしょう。通常のパッチとはかなり異なっています (1 行だけの文章、Perl の正規表現を埋め
込み、削除できず新しいテキストの追加のみ) が、実用上は同じです。
目的は、オリジナルドキュメントにない内容を翻訳済みドキュメントに追加できるようにすることで
す。よくある使用法は、翻訳自体に関する節や、貢献者リスト、翻訳についてのバグレポートのしか
たを追加することです。
追加内容は別個のファイルで提供されなければなりません。最初の行では、生成したドキュメントの
どこに配置するかのヘッダを記述します。追加内容ファイルの残りは、結果のドキュメントの決まっ
た場所にそのまま追加されます。
ヘッダには、以下のようにかなり厳密な文法があります。PO4A-HEADER: で始めなければならず、セ
ミコロン (;) 区切りの key=value フィールドが続きます。空白が重要です。値にはセミコロン (;)
を使えません。引用符で囲んでも使えないことに注意してください。
また恐ろしげに聞こえますが、以下の例は、必要なヘッダ行の記述法を見つける手助けになるでしょ
う。議論の前提として、"About this document" 節の後に "About this translation" 節を追加する
こととします。
以下に有効なヘッダキーを挙げます:
position (必須)
a Perl regexp. The addendum will be placed near the line matching this regexp. Note
that we're speaking about the translated document here, not the original. If more than
a line match this expression (or none), the addition will fail. It is indeed better to
report an error than inserting the addendum at the wrong location.
以下この行を目印と呼びます。追加内容を追加するポイントを追加位置と呼びます。この二つの
ポイントはお互い近くにありますが、同じではありません。例えば、新しい節を挿入する場
合、目印を前節のタイトルとして、po4a にはその節の最後に挿入するよう指示するのが簡単で
す (目印は特定の行がマッチするような正規表現で表すことを覚えておいてください)。
目印に対する追加位置の地域化は、以下で説明する mode, beginboundary, endboundary の各
フィールドで制御します。
この場合、以下のようになります:
position=<title>About this document</title>
mode (必須)
It can be either the string before or after, specifying the position of the addendum,
relative to the position point. In case before is given the insertion point will
placed exactly before the position point. The after behaviour is detailed bellow.
新しい節をマッチした箇所の次に配置したい場合、以下のようにします:
mode=after
beginboundary (mode=after の時のみ使用。この場合必須)
endboundary (同上)
追加内容を後ろに続ける節の最後にマッチする正規表現です。
mode=after の場合、追加位置は目印の後になりますが、すぐ後ではありません! 追加位置で始
まる節の終わりになります。つまり、beginboundary と endboundary のどちらを指定したのか
により、それぞれの引数にマッチした場所の前、後に置かれます。
この場合、以下のように追加して節の終わりに一致するように指定できます:
endboundary=</section>
また、以下のようにして次の節の直前を指定できます:
beginboundary=<section>
どちらの場合でも、</section> の後で <section> の前に追加内容を配置します。ドキュメント
が再構成されても動作するので、前者の方がいいでしょう。
どちらの形態もあるのは、異なるドキュメントフォーマットがあるからです。その中には (使用
したばかりの </section> のような) 節の終わりを示すもの、(man のような) 節の終わりを明
確に示さないものがあります。前者では、boundary が節の最後にマッチするので、追加位置は
その後になります。後者では、boundary が次節の先頭にマッチするので、追加位置はその前に
なります。
これは分かりにくいですが、次の例でよく分かると思います。
今まで説明したことをまとめると、SGML ドキュメントの "About this document" の後に "About
this translation" を追加するには、以下のヘッダ行のどちらかを使用できます:
PO4A-HEADER: mode=after; position=About this document; endboundary=</section>
PO4A-HEADER: mode=after; position=About this document; beginboundary=<section>
以下の nroff 節の後に何か追加したいとします:
.SH "AUTHORS"
この行とマッチする position、そして次節の先頭 (すなわち、^\.SH) とマッチする
beginboundary を入れるべきです。追加内容は、目印の後そして beginboundary とマッチする最
初の行のすぐ前に追加されます。以下のようになります:
PO4A-HEADER:mode=after;position=AUTHORS;beginboundary=\.SH
節全体を追加するのではなく、節の内部 ("Copyright Big Dude" の後など) に何か追加したい場
合、この行とマッチする position、および任意の行とマッチする beginboundary を指定します。
PO4A-HEADER:mode=after;position=Copyright Big Dude, 2004;beginboundary=^
ドキュメントの最後に何か追加したい場合、position はドキュメントの任意の行 (しかし 1 行の
み。ユニークでないと po4a は処理しません) にマッチするように与え、endboundary は何もマッチ
しないように与えます。"EOF" のような単純な文字列を使用せず、ドキュメントにたまたま含まれて
いるものを使用してください。
PO4A-HEADER:mode=after;position=<title>About</title>;beginboundary=FakePo4aBoundary
いずれの場合にも、正規表現であることを忘れないでください。例えば、次の行で終わっている
nroff 節の最後にマッチしたい場合を考えます。
.fi
endboundary として .fi を使用しないでください。明らかに想定していない "the[ fi]le" にも
マッチしてしまいます。この場合の正しい endboundary は ^\.fi$ です。
追加内容が想定通りにうまく動作しない場合、-vv 引数をツールに渡してみてください。追加内容を
配置する際の挙動を表示してくれます。
もっと詳細な例
オリジナルドキュメント (POD フォーマット):
|=head1 NAME
|
|dummy - a dummy program
|
|=head1 AUTHOR
|
|me
そして、以下の追加内容は、(フランス語で)「翻訳者について」節をファイルの最後に追加しま
す。(フランス語の "TRADUCTEUR" は "TRANSLATOR"、"moi" は "me" の意味です)
|PO4A-HEADER:mode=after;position=AUTEUR;beginboundary=^=head
|
|=head1 TRADUCTEUR
|
|moi
|
AUTHOR の前に追加内容を追加するには、以下のヘッダを使用してください:
PO4A-HEADER:mode=after;position=NOM;beginboundary=^=head1
This works because the next line matching the beginboundary /^=head1/ after the section
"NAME" (translated to "NOM" in French), is the one declaring the authors. So, the addendum
will be put between both sections. Note that if later some other section will be added
between NAME and AUTHOR sections, it will break this example making the addenda to be
added before this newly added section.
To avoid this you may accomplish the same using mode=before:
PO4A-HEADER:mode=before;position=^=head1 AUTEUR
一度のプログラム実行でこのすべてを行うには?
po4a を使うことは、それぞれ 3 つ以上の引数が必要な二つの異なるプログラムをユーザが正しい順
番 (po4a-updatepo のあとに po4a-translate) で実行しなければならないということで、少々誤る
傾向にあるということがわかりました。その上、複数のフォーマットが使われているすべてのドキュ
メントを一つだけの PO ファイルにするのは、このシステムでは難しいことでした。
この難しさを解消するために po4a(1) プログラムは設計されました。一度このシステムに移行して
しまえば、簡単な設定ファイルに翻訳用ファイル (po と pot) の位置、原版の位置や形式、翻訳版
の位置を記述するシンプルな設定ファイルを書くことになります。
Then, calling po4a(1) on this file ensures that the PO files are synchronized against the
original document, and that the translated document are generated properly. Of course, you
will want to call this program twice: once before editing the PO files to update them and
once afterward to get a completely updated translated document. But you only need to
remember one command line.
po4a をカスタマイズするには?
po4a モジュールには、モジュールの挙動を変更するオプション (-o オプションで指定) がありま
す。
You can also edit the source code of the existing modules or even write your own modules.
To make them visible to po4a, copy your modules into a path called
"/bli/blah/blu/lib/Locale/Po4a/" and then adding the path "/bli/blah/blu" in the "PERLIB"
or "PERL5LIB" environment variable. For example:
PERLLIB=$PWD/lib po4a --previous po4a/po4a.cfg
注: lib ディレクトリの実際の名前は重要ではありません。
どのように動作しますか?
この章では、保守改良を自信を持って助けていただけるよう po4a 内部の概要を説明します。ま
た、なぜ思ったように動作しないか、どのように問題を解決すればいいかを理解する助けになるかも
しれません。
この大きな絵はなんですか?
po4a のアーキテクチャはオブジェクト指向です (Perl で。イケてる?)。すべてのパーサクラス共通
の派生元は、TransTractor と呼ばれています。このヘンな名前は、ドキュメントの翻訳と文字列の
抽出を同時に行うところから付けられています。
もっと形式張っていうと、入力として翻訳するドキュメントと翻訳が入っている PO ファイルを取
り、結果を以下の二つに分けて出力します。別の PO ファイル (入力ドキュメントから翻訳可能な文
字列を抽出した結果) と、翻訳済みドキュメント (入力したファイルと同じ構造ですが、翻訳可能な
文字列は入力 PO ファイルの内容で置換されているファイル) です。以下に図示します:
入力ドキュメント-\ /---> 出力ドキュメント
\ TransTractor:: / (翻訳済み)
+-->-- parse() --------+
/ \
入力 PO ---------/ \---> 出力 PO
(抽出済み)
この小さな骨状の絵は、po4a アーキテクチャのすべてのコアを表しています。入力 PO や出力ド
キュメントを省略すると、po4a-gettextize になります。両方の入力を行い、出力 PO を無視する
と、po4a-translate になります。
TransTractor::parse() は各モジュールで実装されている仮想関数です。どのように動作するかを説
明するのに、簡単なサンプルがあります。これは、先頭に <p> が付いた段落のリストをパースしま
す。
1 sub parse {
2 PARAGRAPH: while (1) {
3 $my ($paragraph,$pararef,$line,$lref)=("","","","");
4 $my $first=1;
5 while (($line,$lref)=$document->shiftline() && defined($line)) {
6 if ($line =~ m/<p>/ && !$first--; ) {
7 $document->unshiftline($line,$lref);
8
9 $paragraph =~ s/^<p>//s;
10 $document->pushline("<p>".$document->translate($paragraph,$pararef));
11
12 next PARAGRAPH;
13 } else {
14 $paragraph .= $line;
15 $pararef = $lref unless(length($pararef));
16 }
17 }
18 return; # Did not got a defined line? End of input file.
19 }
20 }
6 行目で、2 度目の <p> に遭遇します。それは次の段落のシグナルです。そこで、得られた行をオ
リジナルドキュメントに戻し (7 行目)、これまでに生成された段落を出力に押し出します。9 行目
でそれの先頭の <p> を削除した後、このタグと段落の残りの翻訳を連結して押し出します。
translate() 関数はとてもクールです。引数を出力 PO ファイルに渡して (抽出)、入力 PO ファイ
ルで見つかった翻訳を返します (翻訳)。pushline() の引数の一部で使用するため、この翻訳が出力
ドキュメントに定着します。
クールじゃないですか? 十分シンプルなフォーマットなら、完全な po4a のモジュールを 20 行以下
で作成できます……
Locale::Po4a::TransTractor(3pm) で、これについてもっと知ることができます。
gettext 化: どのように動作しますか?
ここでの考え方は、オリジナルドキュメントとその翻訳を取り、翻訳から抽出した N 番目の文字列
は、オリジナルから抽出した N 番目の文字列の翻訳であるということです。動作するには、双方の
ファイルの構造がまったく同じでなければなりません。例えば、ファイルが以下の構造を持つ場
合、残念ながら翻訳の 4 番目の文字列 (型が「章」) は、オリジナルの 4 番目の文字列 (型が「段
落」) の翻訳だということはまずあり得ません。
オリジナル 翻訳
章 章
段落 段落
段落 段落
段落 章
章 段落
段落 段落
そのため、ファイルを抽出する際、オリジナルファイルからの場合も翻訳ファイルからの場合も
po4a のパーサを使い、二つ目から抽出した文字列を一つ目から抽出した文字列の翻訳として第三の
PO ファイルを構成します。出力した文字列が実際にそれぞれの翻訳となっているかをチェックする
ために、po4a のドキュメントパーサは、ドキュメントから抽出した文字列の構文タイプ情報を出力
すべきです (既存のものはすべてそうしますし、あなたのものもそうするべきです)。さらにその情
報を、双方のドキュメントが同じ構文であるかどうかを確認するのに使用します。先の例では、4 番
目の文字列は片方では段落ですが、もう一方では章見出しであることを検出し、問題を報告できま
す。
理論上、問題を検出した後でファイルを (ちょうど diff がするように) 再同期することは可能で
す。しかし、非同期の前にある、再同期するべき文字列は明確ではなく、何度もまずい結果に終わる
でしょう。以上が、何かまずい場合、現在の実装では再同期を行わず、失敗について詳しく出力する
理由です。問題の修正にはファイルの手修正が必要です。
これだけ用心していても、この部分は非常に間違いやすいです。そのため、このように推測された翻
訳すべてを fuzzy とマークし、翻訳者によりレビューと確認を行うようにしています。
追加内容: どのように動作しますか?
さて、これはかなり簡単です。すべての追加内容が適用されるまで、翻訳済みドキュメントは、直接
ディスクに書かれていませんが、メモリに保管されています。ここに関わるアルゴリズムはかなり率
直です。position 正規表現にマッチする行を探し、mode=before の場合はその前に追加内容を挿入
します。そうでなければ、boundary にマッチする次の行を探し、それが endboundary の場合はその
行の後に、beginboundary の場合はその行の前に追加内容を挿入します。
FAQ
本章ではよく訊かれる質問を分類します。実際、以下のような形でほとんどの質問を定型化できまし
た。「なぜああではなく、このような設計をしたのですか?」 po4a がドキュメントを翻訳する正し
い方法ではないと感じたら、この節を読むようにするべきです。あなたの疑問への答えにならないな
ら、<po4a-devel@lists.alioth.debian.org> メーリングリストで私たちにお問い合わせくださ
い。私たちはフィードバックが大好きです。
なぜ段落ごとに分割して翻訳するのでしょうか?
はい、po4a は段落ごとに区切って翻訳しています (実際、その決定は各モジュールで行っています
が、既存のモジュールは全てそうなっています。また、自作モジュールでも通常はそのようにすべき
でしょう)。この方法には二つの主な利点があります:
• 場面からドキュメントの技術的な部分を隠すと、翻訳者はそこに干渉することができません。翻訳
者に提示するタグなどの目印が少なければ少ないほど、間違いにくくなります。
• ドキュメントを切るのは、オリジナルドキュメントの変更点を隔離する助けになります。オリジナ
ルが変更されたとき、このプロセスにより、翻訳のどの部分が更新が必要なのかを探しやすくなり
ます。
以上の利点をもってしても、段落ごとに区切って翻訳するというアイディアが気に入らない人はいま
す。彼らが恐れていることに対して、以下のように、いくつか回答を用意しています:
• このアプローチは、KDE プロジェクトで成功が実証されました。またそこで翻訳の巨大なコーパス
を作成し、私の知る限りドキュメントを更新しています。
• 翻訳者は翻訳の際に、PO ファイル内の文字列がオリジナルドキュメントと同じ順番であるた
め、まだ文脈を利用できます。そのため、po4a を使う使わないにかかわらず、順番通り訳してい
くのはかなり比較しやすいです。いずれの場合でも、これは私見ですが、書式付きテキストは、真
に読みやすいわけではないので、印刷可能なフォーマットにドキュメントを変換できる状態にして
おくのが、文脈を把握する最善の方法だと思います。
• このアプローチは、プロの翻訳者が採用しています。確かに、彼らはオープンソース翻訳者とは多
少異なる目標を持っています。例えば、内容が変更されるのはまれなので、保守がそれほど重要と
いうわけではありません。
文レベル (またはそれ以下) で分割しないのはなぜですか?
プロ仕様の翻訳ツールは、ドキュメントを文レベルで分割し、以前の翻訳を最大限再利用し、作業の
スピードアップを図るものがあります。これは、同じ文が文脈によっては異なる翻訳になる場合に問
題になります。
段落は、その定義上、文よりも長いです。これにより、二つのドキュメントの同じ段落は、それぞれ
の文脈に関係なく、同じ意味 (と翻訳) になることが、おそらく保証できるでしょう。
文よりも小さい単位で分割するのは、非常にまずいでしょう。なぜまずいのかは、ここで説明するに
は少々長いので、興味のある方は、例えば Locale::Maketext::TPJ13(3pm) の man ページ (Perl の
ドキュメントに同梱) を参照してください。短くするにしろ、各言語は特定の構文規則を持ち、既存
の全言語で (話者の多い 10 言語のうち 5 言語やそれ以下でも) 機能するように文の一部を集めて
文を組み立てる方法はありません。
オリジナルをコメントとして翻訳中 (やその他のところ) につけないのはなぜですか?
一見したところ、gettext はすべての種類の翻訳に適合できるようには見えません。例え
ば、debconf (すべての Debian パッケージが使用する、インストール時の対話インターフェース)
には適合できるようには見えませんでした。この場合、翻訳するテキストはかなり短く (パッケージ
ごとに 1 ダース)、パッケージのインストール前に使用可能でなければならないため、特殊なファイ
ルに翻訳を翻訳を置くことは困難でした。
これが debconf の開発者が翻訳を元と同じファイルに配置する別のソリューションの実装を決めた
理由です。これはかなり魅力的です。例えば、XML のためにこうしたいと思う人さえいます。次のよ
うになります:
<section>
<title lang="en">My title</title>
<title lang="fr">Mon titre</title>
<para>
<text lang="en">My text.</text>
<text lang="fr">Mon texte.</text>
</para>
</section>
しかしこれには問題があるため、現在は PO ベースのアプローチを採用しています。ファイルではオ
リジナルしか編集できず、翻訳はマスターテンプレートから抽出した PO ファイルに置かなければな
りません (そしてパッケージコンパイル時に配置します)。この古いシステムは以下のいくつかの理
由で非推奨です:
• 保守の問題
複数の翻訳者が同時にパッチを提供した場合、それらをマージするのは大変です。
翻訳を適用する必要のある、オリジナルからの変更をどのように検出したらよいでしょう? diff
を使用するには、どの版を元にして翻訳を行ったか記しておかねばなりません。言い換える
と、あなたのファイルには PO ファイルが必要です ;)
• エンコーディングの問題
この解は、ヨーロッパの言語だけが関わる場合には有効ですが、韓国語、ロシア語、アラビア語
(訳注: もちろん日本語も) の導入は、本当に構図を複雑にします。UTF は解になり得ます
が、まだ問題があります。
さらに、この問題を検出するのが難しいのです (言い換えると、「ロシア語の翻訳者のせい
で」韓国語のエンコードが壊れていることを検出するのは、韓国人の読者のみです)。
gettext はこの問題をすべて解決します。
しかし、gettext はこんな用途向けには設計されていません!
そうですね。しかし現在のところ他にもっといい方法がないのです。唯一の代替手段が手動翻訳であ
り、それには保守の問題があります。
gettext を使ったドキュメント翻訳ツールは他に何がありますか?
知る限りでは、以下の二つしかありません:
poxml
KDE の人たちが DocBook XML を扱うために開発したツールです。知る限りでは、ドキュメント
から PO ファイルへ翻訳する文字列を抽出し、翻訳後に注入する初めてのプログラムです。
これは XML のみ、さらに特定の DTD のみを扱えます。リストが一つの大きな msgid になって
しまうため、私はリストの扱いにかなり不満があります。リストが大きくなると、ひとかたまり
の構造をつかみにくくなります。
po-debiandoc
Denis Barbier によって作られたこのプログラムは、多少の異論があるとはいえ po4a SGML モ
ジュールの先駆けといえます。名前の通り、少々非推奨の DTD である DebianDoc DTD のみを扱
います。
以上に対する po4a の主な利点は、簡単に内容を追加できること (欠点かもしれませんが)
と、gettext 化が簡単なことです。
翻訳についての開発者教育
ドキュメントやプログラムの翻訳を行う際、3 つの問題に行き当たります。言語について (皆が二つ
の言語で話せるわけではありません)、技術について (po4a が存在する理由です)、人との連携につ
いてです。すべての開発者が、翻訳の必要性について理解しているわけではありません。立派な意志
があったとしても、翻訳者が作業しやすいやり方を無視する可能性もあります。これを補助するの
に、po4a は参照可能なたくさんのドキュメントを用意しています。
その他の重要な点として、このファイルが何で、どのように使用するのか、を示す短いコメント
で、各翻訳済みファイルが始まるということがあります。これは、話すのも困難な言語の洪水におぼ
れている哀れな開発者を助け、ファイルを正しく扱う助けとなるはずです。
In the po4a project, translated documents are not source files anymore, in the sense that
these files are not the preferred form of the work for making modifications to it. Since
this is rather unconventional, that's a source of easy mistakes. That's why all files
present this header:
| *****************************************************
| * GENERATED FILE, DO NOT EDIT *
| * THIS IS NO SOURCE FILE, BUT RESULT OF COMPILATION *
| *****************************************************
|
| This file was generated by po4a-translate(1). Do not store it (in VCS,
| for example), but store the PO file used as source file by po4a-translate.
|
| In fact, consider this as a binary, and the PO file as a regular source file:
| If the PO gets lost, keeping this translation up-to-date will be harder ;)
同様に、gettext の通常の PO ファイルは、po/ ディレクトリにコピーされる必要があるだけで
す。しかし、これは po4a によって操作されたものに当てはまりません。ここには、開発者が、ド
キュメントの翻訳が存在する場合に、プログラム側の翻訳を削除してしまうという、大きな危険があ
ります (双方を同じ PO ファイルに納めることはできません。これは、ドキュメントはコンパイル時
にのみ翻訳が必要であるのに対して、プログラムは翻訳を mo ファイルとしてインストールしなけれ
ばならないからです)。以上が、po-debiandoc モジュールが以下のヘッダをつけて PO ファイルを提
供する理由です:
#
# ADVISES TO DEVELOPERS:
# - you do not need to manually edit POT or PO files.
# - this file contains the translation of your debconf templates.
# Do not replace the translation of your program with this !!
# (or your translators will get very upset)
#
# ADVISES TO TRANSLATORS:
# If you are not familiar with the PO format, gettext documentation
# is worth reading, especially sections dedicated to this format.
# For example, run:
# info -n '(gettext)PO Files'
# info -n '(gettext)Header Entry'
#
# Some information specific to po-debconf are available at
# /usr/share/doc/po-debconf/README-trans
# or http://www.debian.org/intl/l10n/po-debconf/README-trans
#
gettext ベースアプローチの利点まとめ
• 翻訳はオリジナルと一緒に保存されません。その翻訳が古くなった場合、検出することが可能とな
ります。
• 翻訳は互いに別々のファイルに格納され、異なる言語の翻訳者がパッチの提供やエンコードレベル
の干渉を、互いに受けないようにします。
• 内部的には gettext をベースにしています (が、po4a は非常にシンプルなインターフェースを提
供するので、内部で使用していることを理解する必要はありません)。そんなところで車輪の再発
明をする必要はなく、これは広く用いられているので、バグに悩まされることはないと考えていい
でしょう。
• エンドユーザにとっては何も変化ありません (願わくば翻訳がよりよく保守されるようになる、と
いう事実は置いておいて)。出来上がりの配布されるファイルはまったく同じです。
• 翻訳者は、新しいファイルの文法を学習する必要はなく、好みの PO ファイルエディタ (Emacs の
PO mode や、Lokalize、Gtranslator など) でうまく動作します。
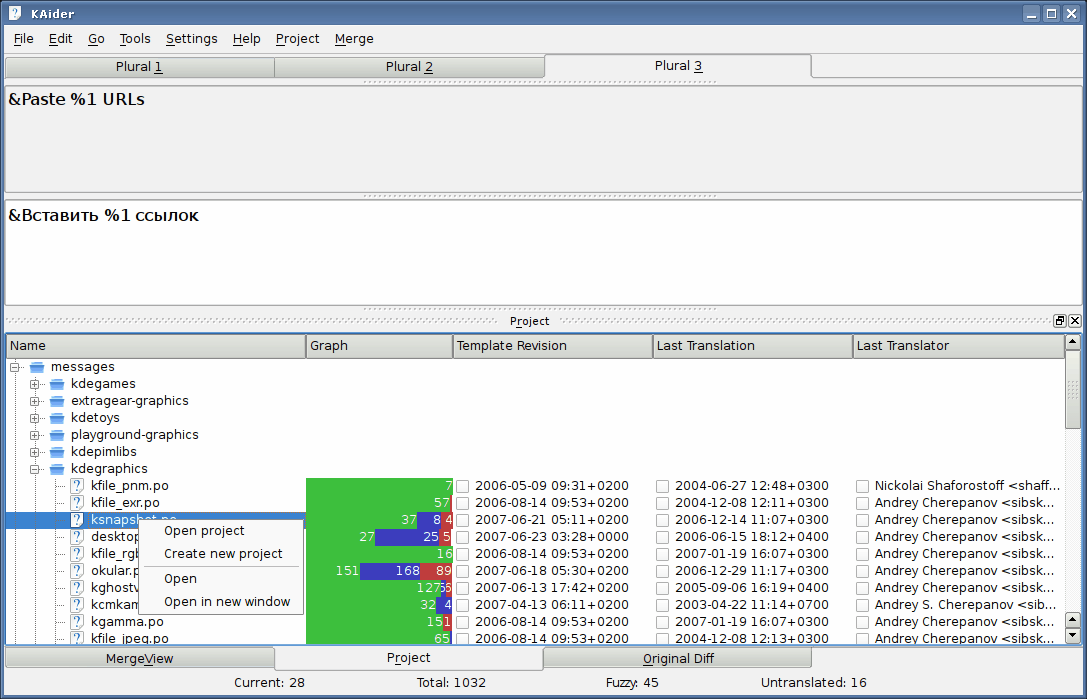
• gettext は、完了しているもの (t)、レビューや更新が必要なもの (f)、そしてまだ翻訳作業が
残っているもの (u) について、統計を取得する簡単な方法を提供しています。以下のアドレスで
いくつか例を見つけることができます:
- http://kv-53.narod.ru/kaider1.png
- http://www.debian.org/intl/l10n/
しかし、すべて問題ないわけではありません。このアプローチには対処するべき欠点もあります。
• 追加内容は……一見して、変です。
• 翻訳したテキストを、段落をここで分割する、二つの段落を片方に結合するといった、あなたの好
みに合わせることができません。しかし、オリジナルに問題があるのであれば、とりあえずバグと
して報告すべきだ、という意見もあります。
• 簡単なインターフェースですが、学習が必要な新しいツールのままです。
One of my dreams would be to integrate somehow po4a to Gtranslator or Lokalize. When a
documentation file is opened, the strings are automatically extracted, and a translated
file + po file can be written to disk. If we manage to do an MS Word (TM) module (or at
least RTF) professional translators may even use it.
{kind=link}
著者
Denis Barbier <barbier,linuxfr.org>
Martin Quinson (mquinson#debian.org)
訳者
倉澤 望 <nabetaro@debian.or.jp>
Debian JP Documentation ML <debian-doc@debian.or.jp>